
-

…˙ŒÔÕ®πŸŒ¢
≈„ƒ„◊•◊°…˙√¸ø∆ºº
ï∂صƒ¬ˆ≤´
…˙ŒÔÕ®πŸŒ¢
≈„ƒ„◊•◊°…˙√¸ø∆ºº
ï∂صƒ¬ˆ≤´
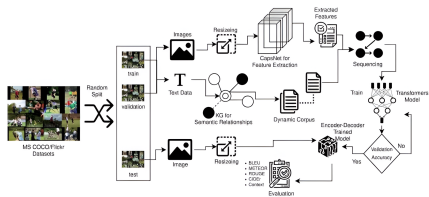
ª˘”⁄Ω∫ƒ“Õ¯¬Á”Î÷™ ∂Õº∆◊µƒ÷™ ∂«˝∂ØÕºœÒ√Ë ˆ…˙≥…∑Ω∑®—–æø
°∂IEEE Access°∑£∫Knowledge?Driven Image Captioning
°æ◊÷ã∫ ¥Û ÷– –° °ø ±º‰£∫2025ƒÍ12‘¬11»’ ¿¥‘¥£∫IEEE Access 3.6
±ýº≠Õ∆ºˆ£∫
°°°°±æŒƒÕ∆ºˆ“ªœÓ¥¥–¬–‘ÕºœÒ√Ë ˆ…˙≥…—–æø°£’Î∂‘¥´Õ≥∑Ω∑®‘⁄º∏∫ŒπÿœµΩ®ƒ£∫Õ…œœ¬Œƒ¿ÌΩ‚∑Ω√ʵƒ≤ª◊„£¨—–æø»À‘±ø™’π¡À÷™ ∂«˝∂ØÕºœÒ√Ë ˆ÷˜Ã‚—–æø°£À˚√«Ã·≥ˆ¡À“ª÷÷»⁄∫œΩ∫ƒ“Õ¯¬Á(Capsule Networks)°¢÷™ ∂Õº∆◊(Knowledge Graphs)∫ÕTransformer…Òæ≠Õ¯¬Áµƒ»˝Ω◊∂ŒøںУ¨‘⁄MSCOCOµ» ˝æðºØ…œ»°µ√¡ÀB4: 49.97, M: 39.14, C: 136.53, R: 74.61µƒ”≈“Ï÷∏±Í°£∏√—–æøÕª∆∆¡À¥´Õ≥±ý¬Î∆˜-Ω‚¬Î∆˜ºÐππµƒœÞ÷∆£¨Õ®π˝º∏∫Œ∏–÷™µƒÃÿ’˜Ã·»°∫Õ∂Øè÷™ ∂ºÏÀ˜£¨œ‘÷¯Ã·…˝¡À√Ë ˆ…˙≥…µƒø’º‰◊º»∑–‘∫Õ”Ô“Â∑·∏ª∂»£¨Œ™∂ýƒ£Ã¨»Àπ§÷«ƒÐ∑¢’π÷π©¡À–¬Àº¬∑°£



 …˙ŒÔÕ®Œ¢–≈π´÷⁄∫≈
…˙ŒÔÕ®Œ¢–≈π´÷⁄∫≈
÷™√˚∆Û“µ’–∆∏
ΩÒ»’∂Øè | »À≤≈ –≥° | –¬ºº ı◊®¿∏ | ÷–π˙ø∆—ß»À | ‘∆’πî | BioHot | ‘∆Ω≤Ã√÷±≤• | ª·’π÷––ƒ | Ãÿº€◊®¿∏ | ºº ıøÏ—∂ | √‚∑— ‘”√
∞Ê»®À˘”– …˙ŒÔÕ®
Copyright© eBiotrade.com, All Rights Reserved
¡™œµ–≈œ‰£∫
‘¡ICP±∏09063491∫≈
