基于检索增强生成的多模块人工智能健康保险支持系统:提升政策透明度与用户体验的创新框架
《Scientific Reports》:A multi module a.i. system for intelligent health insurance support using retrieval augmented generation
【字体:
大
中
小
】
时间:2025年12月05日
来源:Scientific Reports 3.9
编辑推荐:
本文介绍了一项针对健康保险领域复杂政策理解难题的创新研究。为解决保险条款晦涩难懂、用户决策困难等问题,研究人员开发了一套基于检索增强生成(RAG)的多模块AI系统。该系统整合了保险聊天机器人、政策推荐引擎和文档检索三大功能,通过领域适应的语义嵌入和FAISS向量检索技术,实现了政策推荐命中率(Hit@5=1.0)和语义匹配(BERTScore F1=0.84)的优异表现。特别引入的评估代理模块可自动评估回复质量,显著降低了大语言模型的幻觉风险,为保险行业的智能化服务提供了新范式。
在医疗费用持续上涨的当下,健康保险已成为个人和家庭应对健康风险的重要保障。然而在印度,尽管实施了Ayushman Bharat等重大公共卫生计划,截至2024年仍有约7亿人没有健康保险覆盖。造成这种保障缺口的一个重要原因是保险政策的复杂性――保险合同充满技术术语和复杂词汇,普通消费者难以理解。这种透明度的缺乏导致投保人经常误解保障范围,在医疗紧急情况下面临意外的自付费用。
更令人困扰的是,市场上存在众多保险计划,每种都有不同的条款和条件,这使得消费者几乎不可能做出明智决策。虽然人工智能(AI)和自然语言处理(NLP)技术在健康保险领域的应用为解决这些问题提供了可能,但现有系统往往将对话协助、政策推荐和文档检索视为独立任务,缺乏统一架构。
来自印度浦那Symbiosis技术研究所的研究团队在《Scientific Reports》上发表了一项创新研究,提出了一种基于检索增强生成(RAG)的多模块AI系统,专门用于智能健康保险支持。这一系统成功将三大功能模块――保险问答聊天机器人、个性化政策推荐引擎和政策文档检索系统――整合到单一架构中,显著提升了保险信息的可及性和透明度。
研究人员构建了一个包含三个核心模块的统一框架:保险聊天机器人处理一般查询;政策推荐引擎使用RAG架构结合结构化和非结构化政策数据;文档检索模块支持从上传政策中实现条款级搜索。关键创新是引入了评估代理,模拟人类判断从相关性、准确性、清晰度和帮助性四个维度评估回复质量,形成自动化反馈循环。技术核心包括:使用Sentence Transformer生成语义嵌入,FAISS进行高效向量检索,LLaMA 3和DeepSeek R1作为生成模型,以及基于BERTScore、ROUGE-L等多指标的全面评估体系。
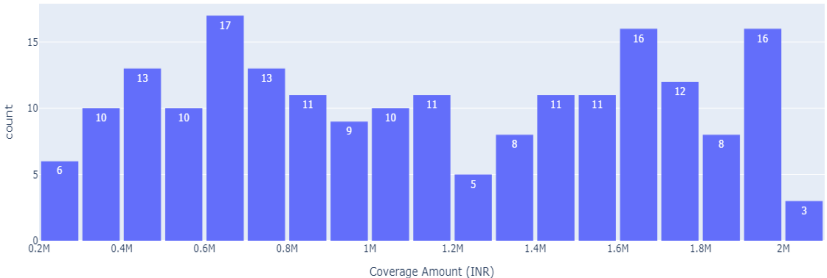
政策推荐模块采用RAG架构,首先通过程序化生成了包含1,000条模拟真实保险政策记录的合成数据集。该数据集涵盖了政策ID、保险公司、产品类型、保障金额、投保人数、年度保费等14个结构化特征,保持了逻辑字段间的相互依赖性,模拟真实世界情况。
研究人员使用all-MiniLM-L6-v2句子转换模型将文本政策描述映射为密集向量,然后通过FAISS(Facebook AI相似性搜索)库建立快速相似性搜索索引。这种设计使得语义相似的政策在向量空间中彼此接近,从而能够高效召回与用户查询最相关的政策。
评估结果显示,该系统在10个多样化保险相关查询的测试中表现出色:Hit@5达到1.0(所有查询都成功检索到至少一个相关策略),Recall@5为0.833,NDCG@5为0.69。尽管Precision@5相对较低(0.333),但语义评估显示BERTScore F1高达0.84,表明生成回复与参考答案在语境和语义上非常接近。
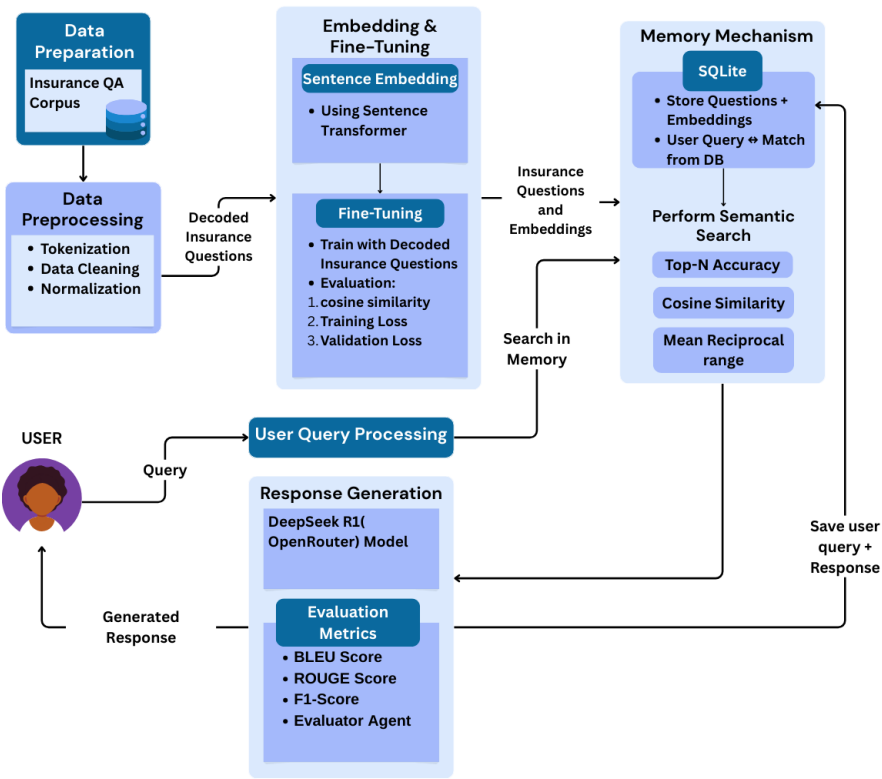
保险聊天机器人模块采用多阶段自然语言处理流程,以Insurance QA语料库为基础,该语料库包含保险领域的真实世界问题。系统通过预训练的Sentence Transformer将输入问题转换为密集向量表示,并存储在SQLite数据库中以实现高效检索。
该系统支持语音和文本输入,具有记忆机制,能够检索历史交互记录。当用户提出新查询时,系统首先尝试通过嵌入相似性进行记忆搜索,若无匹配则转向基于余弦相似度的语义搜索。最终响应通过OpenRouter平台上的DeepSeek R1语言模型生成,并存储以备未来召回。
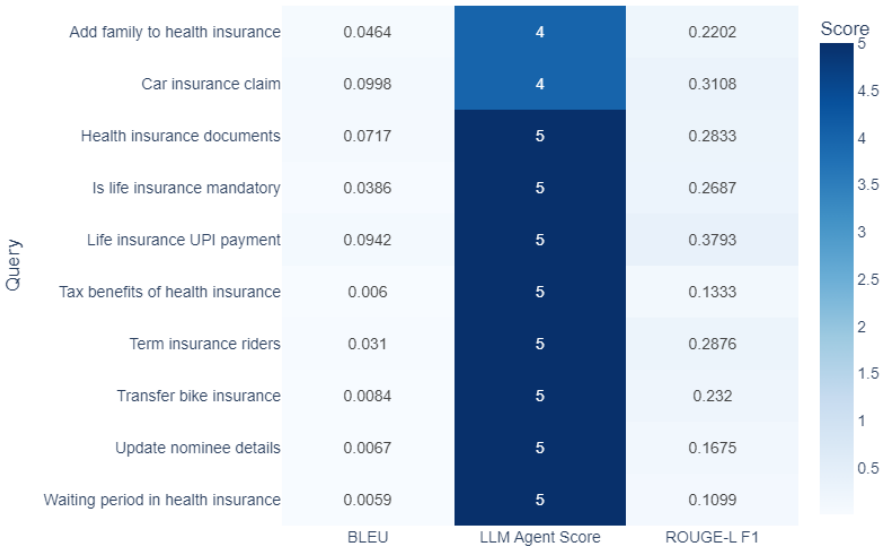
评估结果表明,虽然BLEU分数较低(表明措辞变化较大),但ROUGE-L F1分数中等,而LLM代理评分高达4-5分(满分5分),证明系统能持续以自然对话方式提供正确信息。
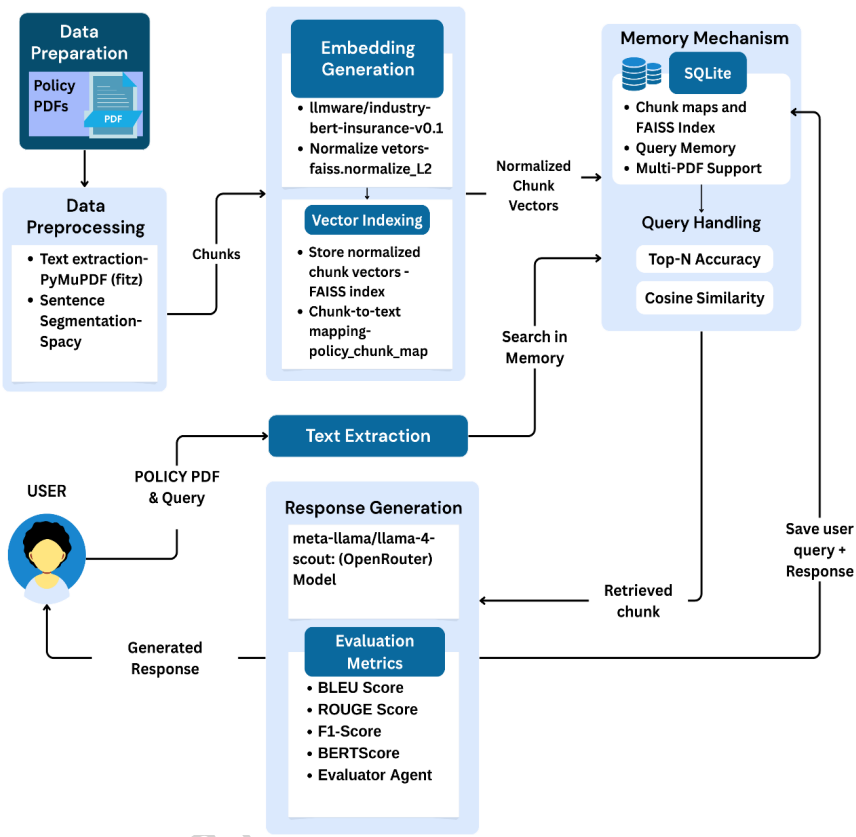
政策文档检索模块支持用户上传PDF格式的保险政策文件,并通过PyMuPDF库提取文本内容。文本经SpaCy NLP库分句后,被组合成语境一致的块,然后通过领域特定的转换模型llmware/industry-bert-insurance-v0.1生成上下文嵌入。
这些嵌入向量经L2归一化后存入FAISS索引(IndexFlatIP),实现基于内积计算的快速相似性搜索。用户查询经相同模型编码后,与FAISS索引比对找到最相似的块,最后由meta-llama/llama-4-scout模型生成易于理解的摘要和解释。
评估数据显示,该模块的BERTScore F1达到0.8443,表明生成回复与参考答案间具有强大的语义对齐性,尽管措辞可能不同,但能有效捕捉含义。
本研究的一个突出创新是引入了评估代理,作为RAG反馈循环中的自主评估机制。该代理使用大语言模型驱动的评估标准,从相关性、准确性、清晰度和帮助性四个维度评估生成回复,模拟专家人类判断。
评估代理不仅提供定性性能测量,还作为自我纠正的反馈组件,允许系统生成行为的迭代优化,无需持续人工监督。这种自动化质量控制过程代表了自评估领域适应LLM系统设计中的新方法创新。
该研究的核心贡献在于提出了一个统一的多模块架构,将对话问答、个性化政策推荐和条款级文档检索三大功能整合到单个检索生成框架中。与以往孤立处理这些任务的实现不同,该系统通过共享嵌入和基于FAISS的通用检索主干,实现了跨模块的语义一致性和数据重用。
在技术层面,研究开发了专门针对健康保险信息优化的领域适应检索增强生成管道,使用基于Transformer的句子嵌入在InsuranceQA语料库和领域特定的健康政策文本上进行微调,从而能够更准确地检索语义相关的条款和政策选项。
在实际应用层面,用户测试显示15名参与者的满意度达89%,响应延迟低于1.8秒,证实了系统实时部署的可行性。系统界面直观易用,用户可根据需要选择文档搜索、政策推荐或与保险聊天机器人对话。
这项研究通过合成语义检索、大语言生成和评估驱动反馈,为保险等受监管、文件密集型领域的数字服务建立了可扩展的新范式。研究结果验证了RAG驱动架构在保险等领域的有效性,其中事实准确性和可解释性至关重要。未来工作将侧重于结合真实和合成数据的混合数据集,以进一步增强系统鲁棒性,并将该框架扩展至法律合同、银行和医疗政策解读等相邻领域。
 生物通微信公众号
生物通微信公众号
 生物通新浪微博
生物通新浪微博
今日动态 |
人才市场 |
新技术专栏 |
中国科学人 |
云展台 |
BioHot |
云讲堂直播 |
会展中心 |
特价专栏 |
技术快讯 |
免费试用
版权所有 生物通
Copyright© eBiotrade.com, All Rights Reserved
联系信箱:
粤ICP备09063491号