
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
基于生成式人工智能的化学分类程序合成:构建可解释的ChEBI化学类别程序本体(C3PO)
【字体: 大 中 小 】 时间:2025年10月03日 来源:Journal of Cheminformatics 5.7
编辑推荐:
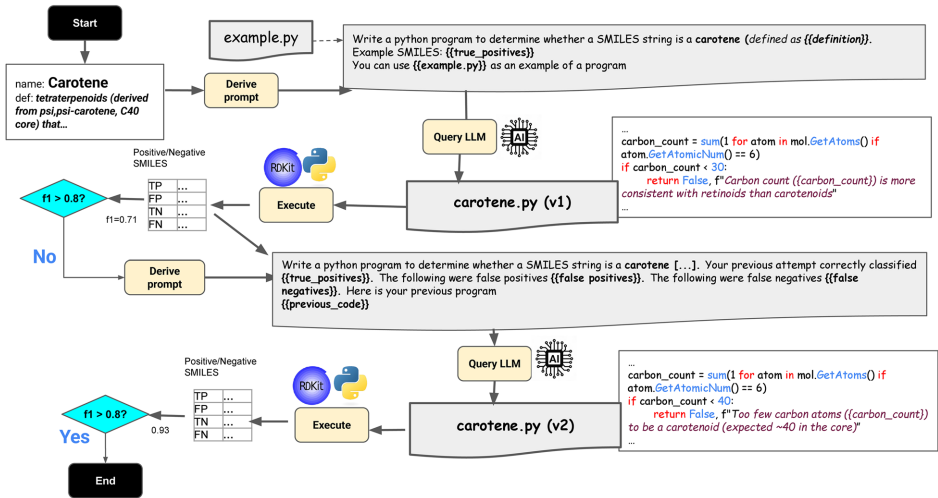
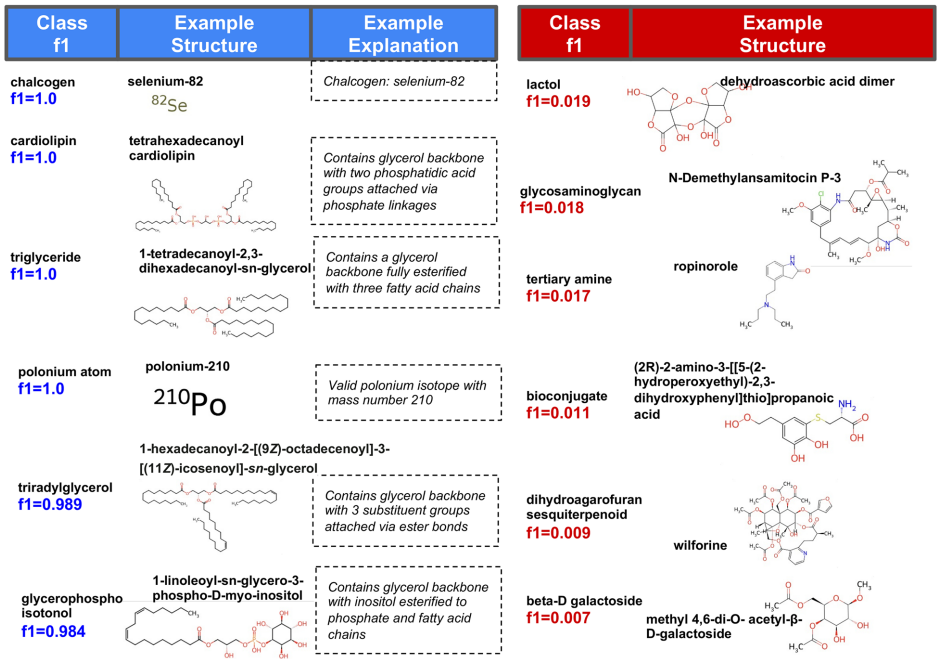
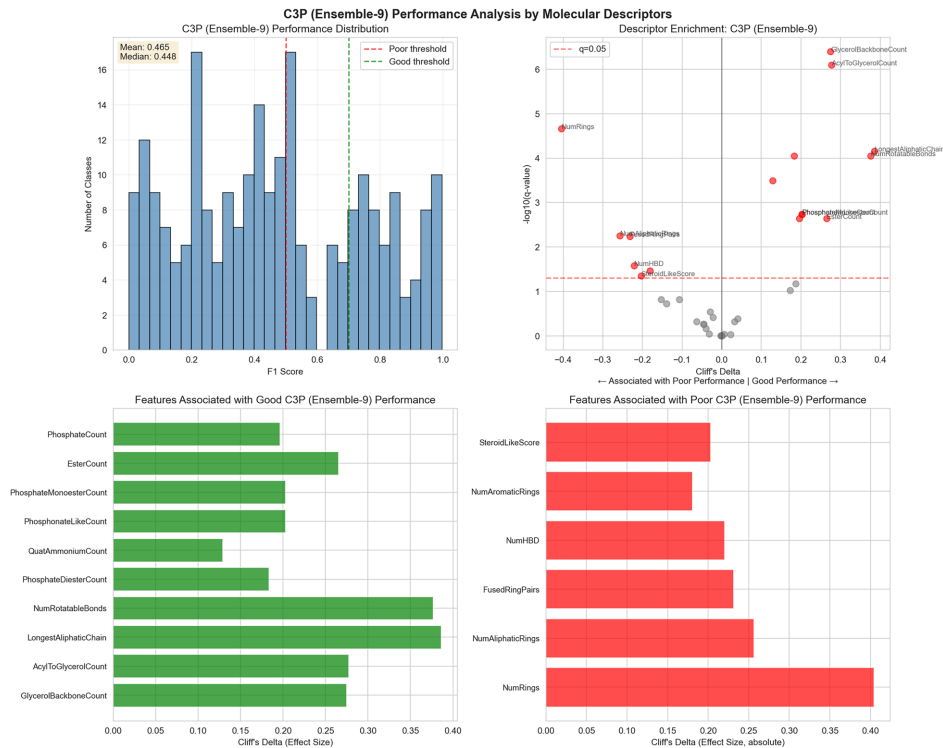
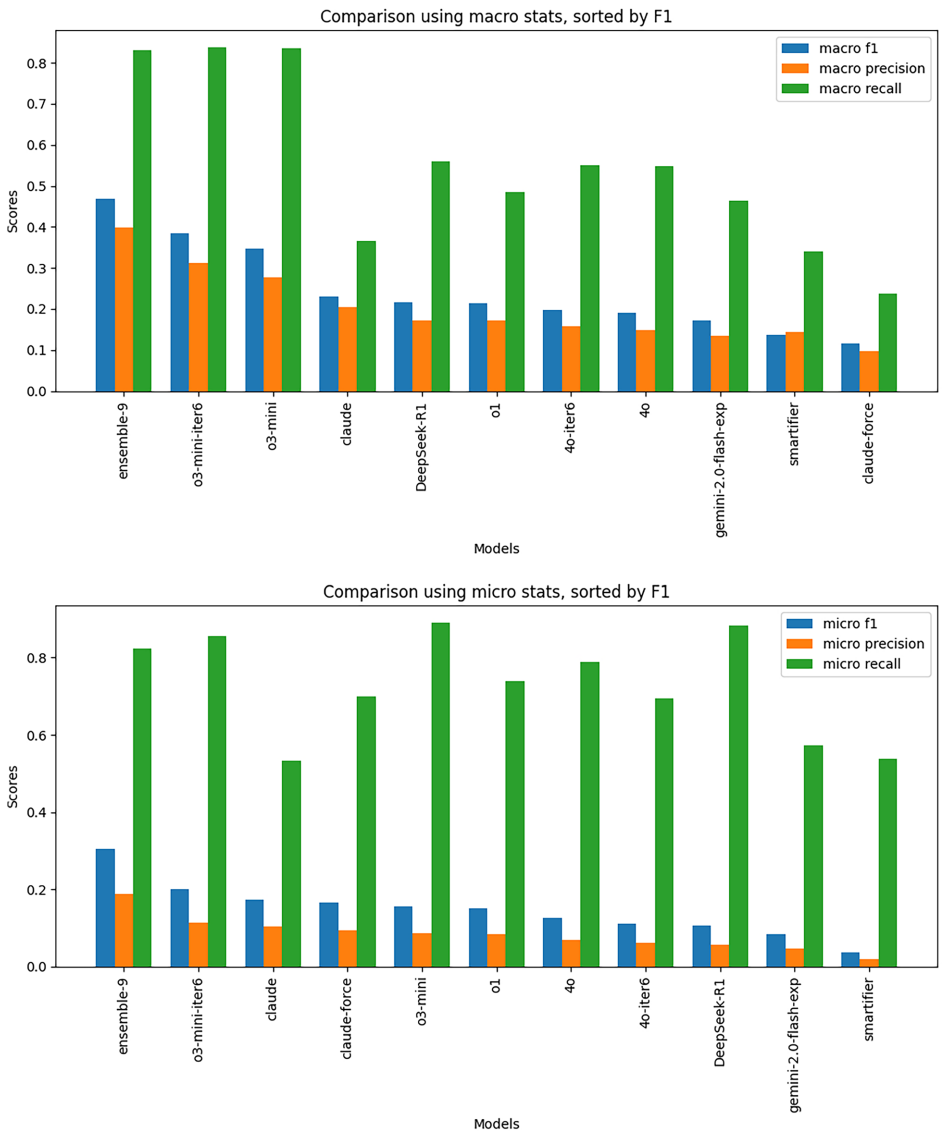
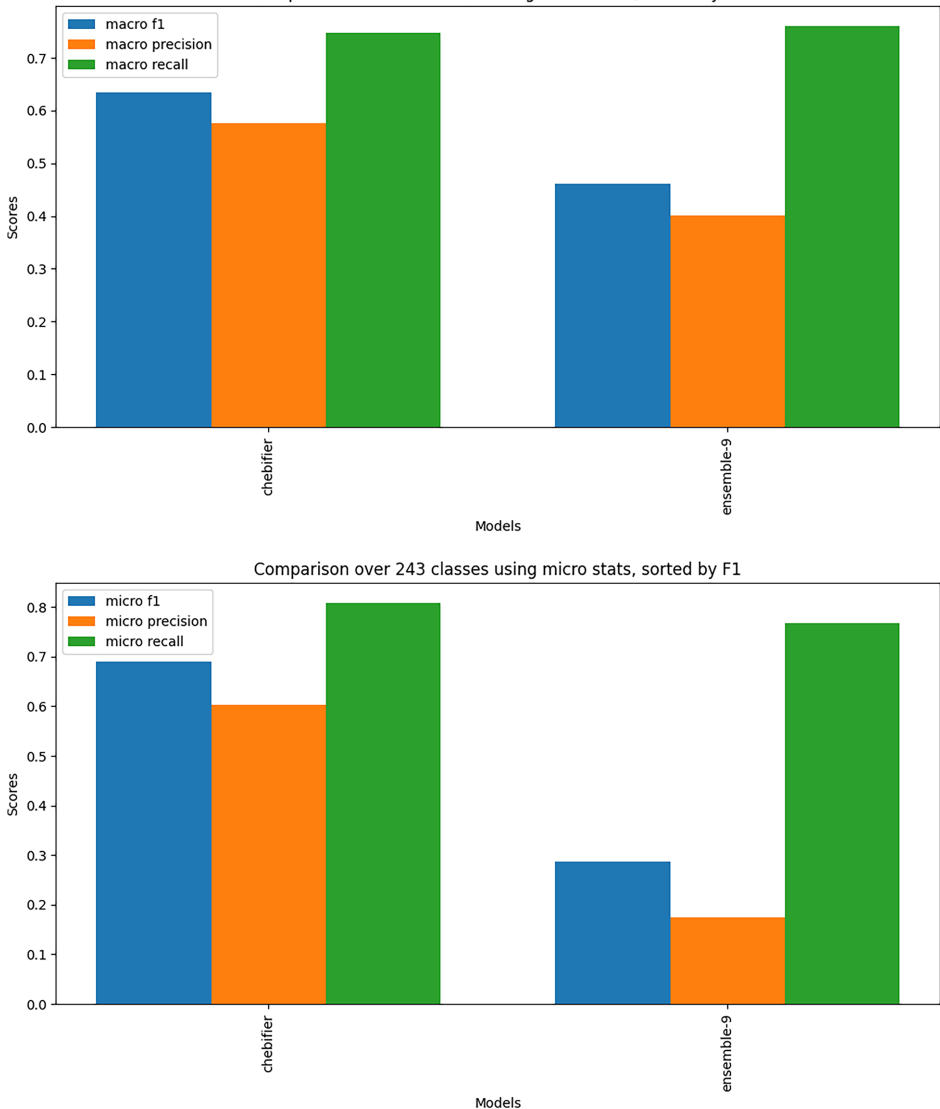
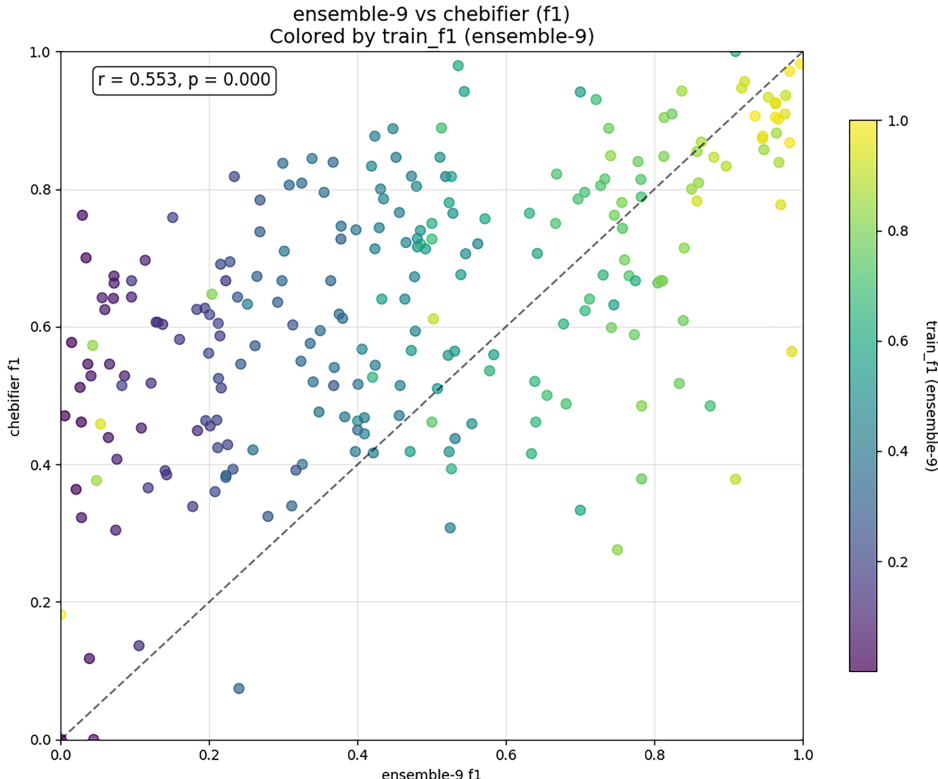
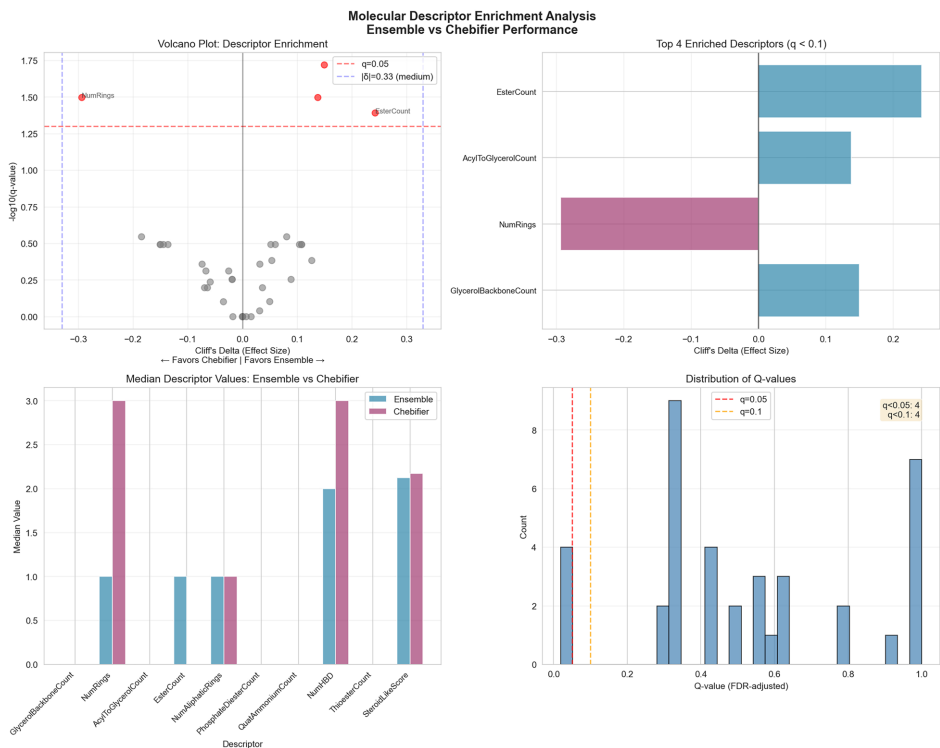
本研究针对化学结构分类中人工方法效率低下与现有自动化方法可解释性不足的问题,开发了一种利用生成式AI自动编写化学分类程序的新方法。研究人员通过Learn-Execute-Iterate-Adapt(LEIA)流程,成功为ChEBI数据库中的化学类别生成了可执行的Python分类程序,构建了ChEBI化学类别程序本体(C3PO)。实验表明C3PO在保持可解释性的同时,性能优于基于SMARTS的简单分类器,虽略低于最先进的深度学习模型,但提供了互补优势。该方法为化学数据库 curation 提供了可解释的自动化工具,显著提升了分类效率和透明度。
 生物通微信公众号
生物通微信公众号
知名企业招聘

