
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
ChatGPT-3.5在BPH术后患者咨询应答中的有效性评估:一项关于人工智能医疗指导可靠性的前瞻性研究
【字体: 大 中 小 】 时间:2025年10月02日 来源:Scientific Reports 3.9
编辑推荐:
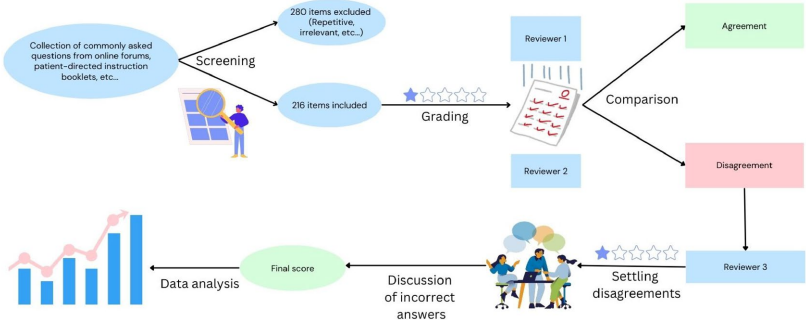
本研究针对人工智能在医疗咨询中的可靠性问题,评估了ChatGPT-3.5对良性前列腺增生(BPH)术后患者查询的应答质量。研究人员收集了496个常见术后问题,涵盖TURP、Aquablation等8种手术方式,发现78.2%的回答准确全面,但仍有21.8%存在信息不全或错误。研究表明AI虽具潜力,但需进一步优化以确保患者安全。

 生物通微信公众号
生物通微信公众号
知名企业招聘

