
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
Nat Commun | 基于化学微扰转录组自监督表征学习的药物筛选
【字体: 大 中 小 】 时间:2024年07月02日 来源:中国科学院上海药物研究所
编辑推荐:
2024年6月25日,中国科学院上海药物研究所郑明月课题组在Nature Communications期刊发表题为“Deep representation learning of chemical-induced transcriptional profile for phenotype-based drug discovery”的研究论文
2024年6月25日,中国科学院上海药物研究所郑明月课题组在Nature Communications期刊发表题为“Deep representation learning of chemical-induced transcriptional profile for phenotype-based drug discovery”的研究论文。该研究提出基于自监督表征学习的深度生成模型TranSiGen,学习化学微扰转录组表征用于药物表型筛选。

基于表型的筛选是药物研发中的重要方法之一,侧重于化合物的更全面的细胞响应,提供对疾病机制更全面的理解,并有可能发现新的药物作用机制和治疗机会。高通量RNA测序技术促进了大规模微扰转录组的产生。虽然化学微扰转录组能够提供对药物作用机制更全面的理解,化合物和细胞系组合的复杂性限制了通过高通量实验进行彻底的探索。已有研究者利用大量公共数据构建深度学习模型用于预测微扰转录组,然而转录组数据中固有的高噪声往往掩盖了真正的扰动信号,使得现有模型难以从中提取有意义的信息。
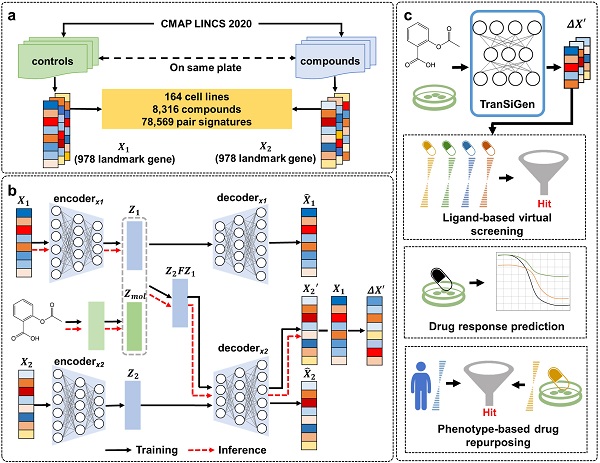
图1.TranSiGen架构和下游应用
在该项研究中,研究团队提出基于变分自编码器的TranSiGen模型,利用自监督表征学习进行转录谱的去噪和重建,并且用于推断新的微扰转录谱(图1)。TranSiGen同时学习三个分布,包括没有扰动的本底谱、化学微扰转录谱以及它们之间的映射关系。这种自监督方法有效地减少了数据中的噪声,并揭示了潜在的扰动信号。广泛的评估表明,TranSiGen在推断本底谱、化学微扰转录谱以及相应的差异基因表达(DEGs)方面优于现有模型。作为一种统一的表型信息表征方式,TranSiGen推断的差异基因表达可以有效地捕获细胞和化合物的特征。
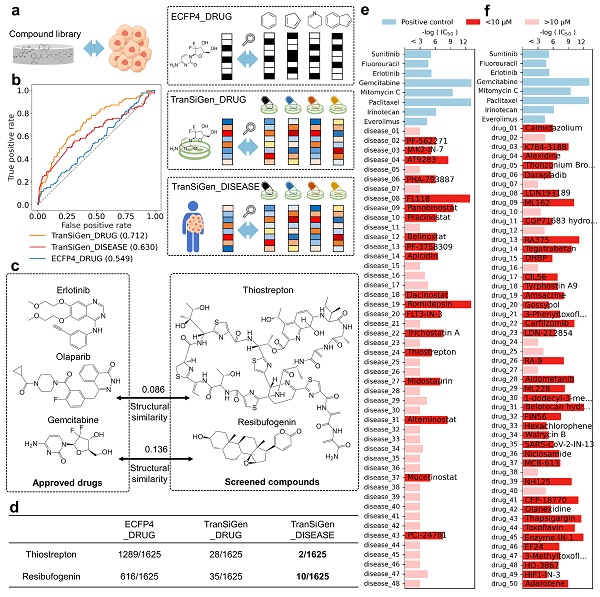
图2.基于表型的药物重定向
此外,TranSiGen表征在各种下游任务中展现出了有效性,包括基于配体的虚拟筛选、药物响应预测和基于表型的药物重定向。利用TranSiGen进行抗胰腺癌活性化合物虚拟筛选(图2),体外实验验证结果展现出高命中率,这一结果显示了TranSiGen在药物筛选方面的潜力。
本研究引入深度生成模型TranSiGen,旨在通过自监督表征学习克服转录谱中固有噪声和混杂因素的局限,提供了一种标准化方法来表征与细胞环境和化合物效应相关的表型信息。TranSiGen表征在各种下游任务中证实了其有效性,并在基于表型的药物重定向及体外验证中展现了其在现实世界药物发现场景中的前景。
上海药物所博士童筱雏为论文的第一作者。上海药物所药物发现与设计中心(DDDC)郑明月研究员、李叙潼副研究员与张素林副研究员为论文通讯作者。本研究得到了国家自然科学基金、国家重点研发计划、上海药物所与上海中医药大学中医药创新团队联合研究项目、中国科学院青年创新促进会会员项目以及上海市科技重大专项资助。感谢国家蛋白质科学研究(上海)设施规模化蛋白质制备系统工作人员提供的技术支持和帮助。

