
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
Chem Sci | 微调大语言模型:化学文本挖掘新方法
【字体: 大 中 小 】 时间:2024年06月18日 来源:中国科学院上海药物研究所
编辑推荐:
2024年6月7日,中国科学院上海药物研究所郑明月课题组于Chemical Science发表题为“Fine-tuning Large Language Models for Chemical Text Mining”的研究论文
2024年6月7日,中国科学院上海药物研究所郑明月课题组于Chemical Science发表题为“Fine-tuning Large Language Models for Chemical Text Mining”的研究论文。该研究团队在五项化学文本挖掘任务上对多个大语言模型的能力进行了全面综合的探究,展现了微调大语言模型成为一种通用高效的生成式文本挖掘方法,为大模型的落地应用提供参考。?

化学文献中蕴含着丰富数据,通过文本挖掘技术提取关键化学信息从而构建庞大的数据库,不仅能够为实验化学家提供详尽的物理化学性质和合成路线指引,还能够为计算化学家提供丰富的数据和洞见用于模型构建和预测。然而,由于化学语言的复杂性和论文风格的多样性,从化学文献中提取结构化数据是一项极具挑战性的任务。为了解决这一难题,许多文本挖掘工具应运而生,助力科学研究迈向新的高峰。然而,这些针对特定数据集和语法规则构建的文本提取模型往往缺乏灵活的迁移能力。近两年,以ChatGPT为代表的大语言模型(LLM)风靡全球,引领了人工智能和自然语言处理领域的快速发展。利用通用大语言模型强大的文本理解和文字处理能力,从复杂化学文本中灵活准确地提取信息,有望解放数据标注工人的劳动力,加速领域数据的标准化和结构化收集,推动化学领域的研究和发展。
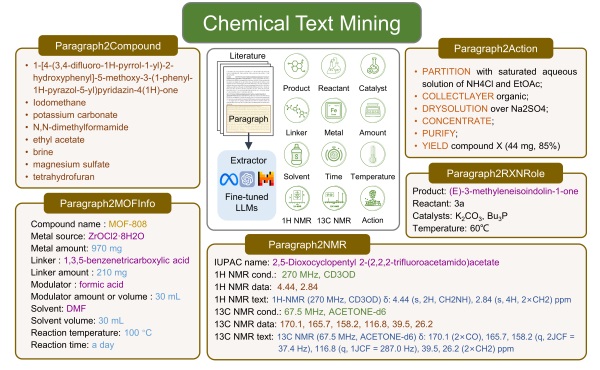
图1. 化学文本段落中蕴含丰富化学信息,五项结构化提取任务的数据形式。
本研究在五项化学文本挖掘任务上对多个大语言模型的能力进行了全面综合的探究,任务包括化合物实体识别、反应角色标注、金属有机框架(MOF)合成信息提取、核磁共振波谱(NMR)数据提取和反应合成段落转换动作序列。研究人员基于多种大语言模型(LLMs)探索了多种策略,利用零样本、少样本提示工程来指导GPT-4和GPT-3.5-turbo,并对GPT-3.5-turbo、Llama3、Mistral、T5和BART等语言模型进行参数高效微调或全量参数微调。结果显示,经过全参微调的LLMs表现出令人印象深刻的性能,同时显著减少了对提示工程的依赖性。其中,微调后的 GPT-3.5-turbo 在所有任务中都表现出色,完全匹配准确度达到了 69% 到 95%,甚至优于那些基于大量领域内数据自适应或任务自适应预训练后微调的特定模型。值得注意的是,经过微调的开源大模型如 Mistral 和 Llama3 也表现出了一定的竞争力,可以在本地部署大模型以高效准确地提取私有数据。这项研究强调了微调LLM在化学文本挖掘中的通用性、稳健性、准确性和低代码特性。鉴于这些优点,微调LLMs作为灵活有效的生成式信息提取方法,有望加速各领域的数据收集和科学发现。
上海药物所博士研究生张玮、南京中医药大学硕士研究生王庆功为本文共同第一作者。上海药物所郑明月研究员、博士后付尊蕴为本文通讯作者。本研究得到了国家自然科学基金、国家重点研发计划、上海药物所与上海中医药大学中医药创新团队联合研究项目、上海市超级博士后计划、上海市科技重大专项等项目的资助。
原文链接:https://pubs.rsc.org/en/Content/ArticleLanding/2024/SC/D4SC00924J

