
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
工学院宋洁课题组研究成果入选Cell子刊Patterns封面文章,提出数据价值研究新范式
【字体: 大 中 小 】 时间:2024年06月10日 来源:北京大学新闻网
编辑推荐:
该研究提出了一种新型智能化数据价值研究范式,通过结合深度学习技术,构建了多源异构数据的标准化价值输出模型;基于强化学习理论,实现了针对任务效用的参数更新算法。针对监督式数据价值计算中存在的不可微分性、采样效率低和次优性等问题,研究团队提出了一个整合惩罚项的近端策略优化算法,有效解决了算法收敛性差的瓶颈,实现了在各种场景下数据价值的精确识别。
随着数字经济的持续发展,数据已成为推动现代化经济建设的关键性资源。据预测,2025年全球数据资产总量将超过175ZB。在大数据的环境下,多层次、多尺度的价值关系尚未被完全发掘并应用。从根本上说,数据的价值源于对应用对象和研究任务的明确界定,而这些任务的执行效果则直接受制于多源异构数据的质量。高质量的数据样本可以显著提升学习性能和任务的完成度,反之弱因果关系或无关数据可能削弱学习的准确性。尽管信息熵、离群值诊断和Shapley值等模式化方法已广泛用于数据特征的优化与价值评估,然而难以准确反映数据在不同任务需求下的差异性贡献。因此,亟需在统计学与经济学的基础上,研发出场景驱动的数据价值评估体系,以灵活地解析多源异构数据在复杂任务中的价值实现机制,为数据资源的智能化使用提供科学基础。

图1 相关成果入选Cell旗下Patterns期刊封面文章
5月10日,北京大学工学院宋洁课题组在数据科学权威期刊Cell子刊Patterns发表了题为“Unveiling Value Patterns via Deep Reinforcement Learning in Heterogeneous Data Analytics”的研究论文,并入选当期封面文章。该研究提出了一种新型智能化数据价值研究范式,通过结合深度学习技术,构建了多源异构数据的标准化价值输出模型;基于强化学习理论,实现了针对任务效用的参数更新算法。针对监督式数据价值计算中存在的不可微分性、采样效率低和次优性等问题,研究团队提出了一个整合惩罚项的近端策略优化算法,有效解决了算法收敛性差的瓶颈,实现了在各种场景下数据价值的精确识别。具体针对学习类模型的训练任务而言,该范式能有效地识别出高/低质量的训练数据,筛选出高质量数据集以显著提升模型效能。研究还深入探讨了包括模式迁移性在内的数据价值深层规律,为智能化数据分析与数据系统决策领域提供了新的视角和方法。
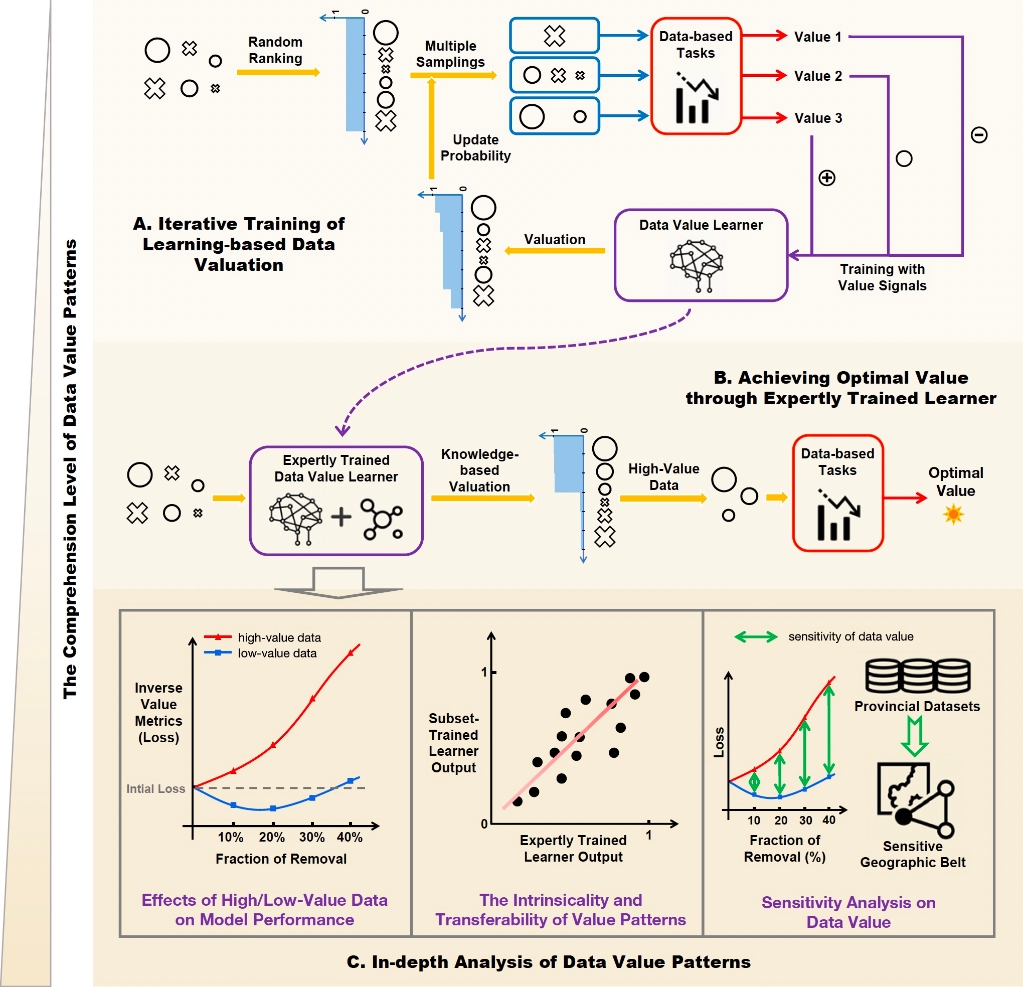
图2 一种创新的数据价值研究范式,系统地从价值测算到模式分析,逐层解析数据在任务中的价值作用及其规律
为验证所提出的学习式数据价值评估方法(Learning-based Data Valuation,LDV)的适用性,研究选择了多个跨领域的数据集,并设计了相应的分析模型及评价指标。任务涵盖了基于人口普查数据的收入分类评级、森林火灾规模预测、个体肥胖水平评估,以及心力衰竭患者的临床特征分析。实验结果表明,相较于传统方法,LDV在移除低/高价值数据后对提高任务效能表现出更显著的正/负向影响,证明了其在识别各种任务中数据的复杂价值模式的精确性。
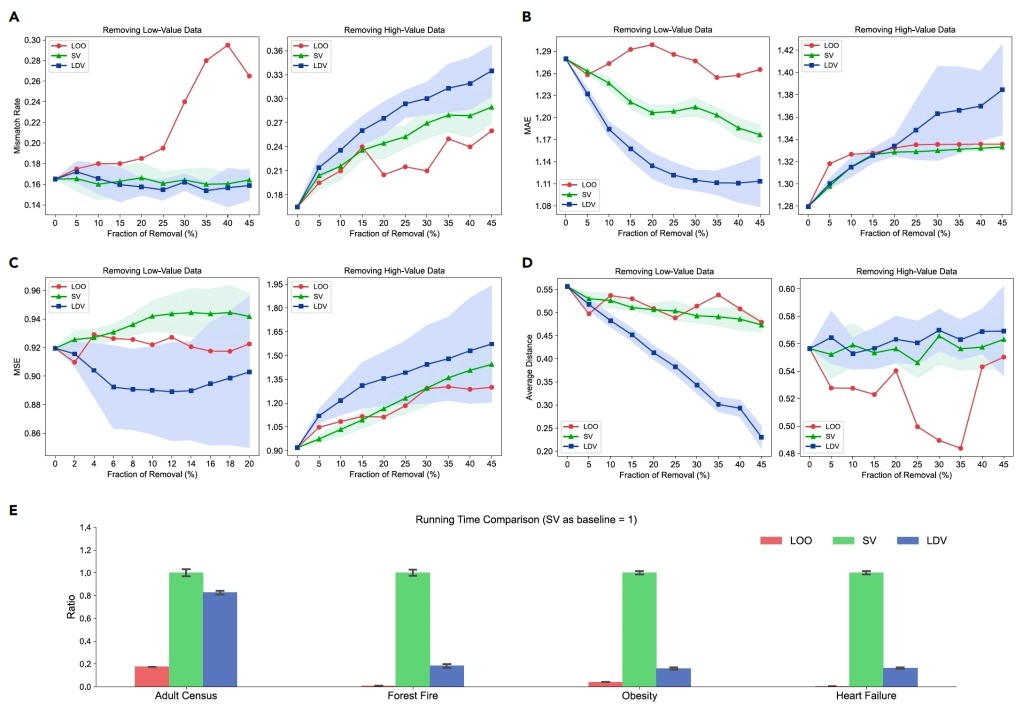
图3 本图展示了学习式数据价值评估方法(LDV)相较于传统的Shapley值法(SV)和留一法(LOO),在不同任务中数据价值规律的精准与高效解析。ABCD分别顺序代表上述四个任务,E展示了各方法在计算效率上的对比
进而,以日前24小时风电预测为任务,该研究系统分析了我国省级数值气象与风电功率时间序列的数据价值分布规律。研究通过探究在移除等量高/低价值数据后,各省风电预测精度变化的差异,开发了一种评估数据价值敏感性的方法。研究结合地理气候因素及价值分布特征,提出了我国从西南至东北的数据价值敏感性“地理带”的区域性数据治理策略,以优化能源大数据系统决策并提高决策精确性。
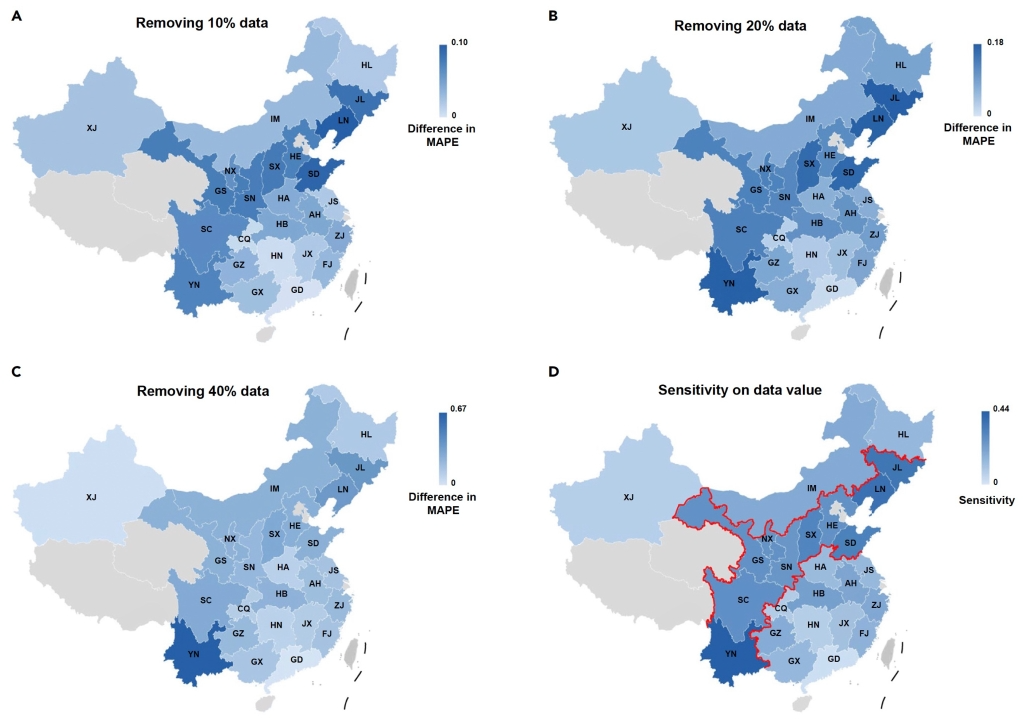
图4 我国省级可再生能源数据的价值模式及敏感性分析
该研究开发了一种普适性的数据价值评估方法,首次实现了跨领域数据价值的精确测算,旨在通过智能化手段实现数据资源的价值化解析和针对性使用。基于价值模式的进一步分析,该研究成果有望在多领域推动数据驱动的价值实现,并为大数据治理提供政策建议。宋洁课题组博士研究生王衍之为该论文第一作者,通讯作者为宋洁和大数据国家工程实验室王剑晓,合作者包括工学院高锋。该研究得到了国家重点研发计划和国家自然科学基金的支持。

