
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
基于新型存储器的模拟矩阵计算研究进展
【字体: 大 中 小 】 时间:2022年08月30日 来源:北京大学人工智能研究院
编辑推荐:
近日,类脑智能芯片研究中心孙仲研究员指导本科生在国际电路与系统领域顶级期刊IEEE Transactions on Circuits and Systems I: Regular Papers(TCAS-I)发表研究论文,论文题目为“Modeling and Mitigating the Interconnect Resistance Issue in Analog RRAM Matrix Computing Circuits”。 信息科学技术学院2019级本科生罗宇标同学为该论文的第一作者,也是学校第一次以本科生为第一作者在IEEE TCAS-I上发表学术论文。图 1 A...
近日,类脑智能芯片研究中心孙仲研究员指导本科生在国际电路与系统领域顶级期刊IEEE Transactions on Circuits and Systems I: Regular Papers(TCAS-I)发表研究论文,论文题目为“Modeling and Mitigating the Interconnect Resistance Issue in Analog RRAM Matrix Computing Circuits”。 信息科学技术学院2019级本科生罗宇标同学为该论文的第一作者,也是学校第一次以本科生为第一作者在IEEE TCAS-I上发表学术论文。
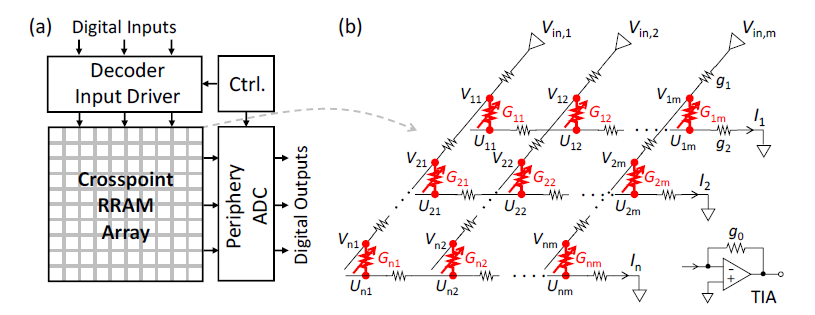
图 1 AMC架构及包含互连电阻的RRAM阵列
阻变存储器(RRAM)具有突出的模拟电导特性,它常采用的交叉阵列架构能够自然地用电导值表示矩阵元素,再通过利用运算放大器形成局部或全局的反馈回路,实现各种基本的模拟矩阵运算(AMC),如矩阵-向量乘法(MVM)。在实际电路中,器件/电路的非理想因素如互连电阻、源漏电阻、器件电导随机性等会极大地影响计算精度(图1)。MVM电路的快速仿真与性能优化对于大规模系统集成的研究具有重要的基础意义。
在MVM电路中,由于互连电阻与交叉点RRAM器件紧密耦合,对它的仿真尤为困难。在传统的SPICE仿真中,利用改进节点分析法(MNA)求解的时间复杂度为O(n6)(n为阵列的行/列数),极大地限制了大规模电路仿真的效率。基于电路中的物理定律,该论文提出了一种高效的迭代算法,能够在不损失仿真精度的情况下极大地减少仿真时间。图2展示了迭代算法以及它与SPICE仿真速度的比较。对于n×n的交叉阵列,由于每次迭代只需要计算n×n的矩阵-矩阵乘法,迭代算法的时间复杂度仅为O(n3),相比于SPICE实现了二次方加速,在较大规模的仿真中表现出3个数量级的速度提升。另外,该工作还分析了迭代算法的收敛性问题、考虑源漏电阻以及其它电路结构改变时迭代算法的变形等,扩展该迭代算法的适用范围。

图2迭代算法及其与SPICE仿真速度的比较。
在RRAM模拟矩阵计算电路中,由于RRAM的电导值只能为正,对于含负元素的矩阵运算,通常需要将矩阵分解为两个正元素矩阵相减的形式。传统的电路结构主要分为行拆分模式(row-wise splitting,RS)和列拆分模式(column-wise splitting,CS),各自需要较多的硬件资源,如运放和模拟反相器。为了简化电路的构成与操作,该工作提出了一种在行拆分(RS)基础上,基于电导补偿策略(conductance compensation,CC)实现的MVM电路(图3)。相比于RS和CS电路,CC-RS电路通过在阵列中增加一列补偿电导,使得每一行上只需要一个运放来完成运算,从而显著降低电路所需的面积和功耗。同时在计算精度的测试中,CC-RS电路也表现出更好的性能,当输入向量的极性相同时,CC-RS电路表现出对互连电阻、器件电导随机性更高的容忍度。
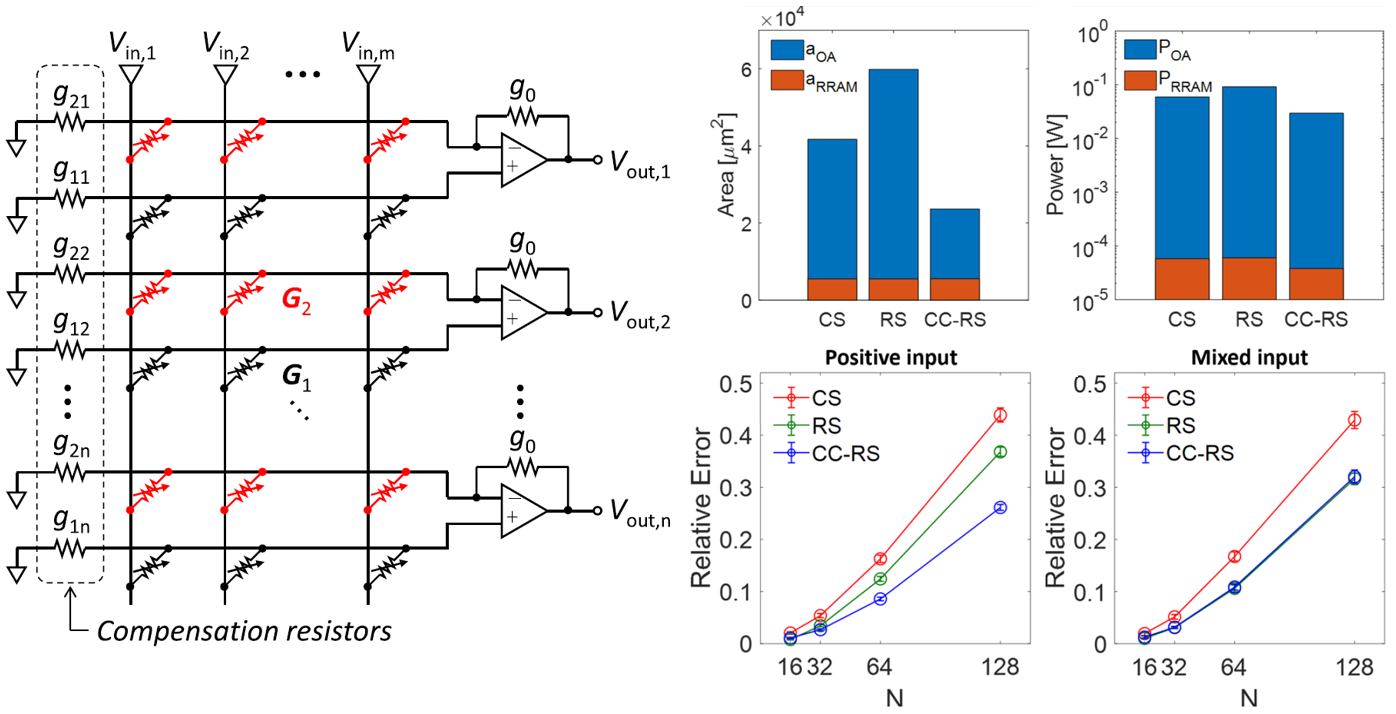
图 3 CC-RS电路结构与3个电路面积、功耗及计算误差对比
该工作进一步用离散傅里叶变换(DFT)的实例分析了3个电路的实际性能。对于CC-RS电路,补偿电导的值需要通过计算拆分后的两个矩阵的行加和之差得到。但是,由于DFT矩阵中(除第一行外)每一行正、负元素绝对值相等的特性,无需预先计算行加和,能够很自然地完成从DFT矩阵到CC-RS电路的映射(图4)。最后,该工作重点比较了在考虑互连电阻、器件电导随机性以及源漏电阻等非理想因素影响下3个电路的计算精度。相比于CS和RS电路,CC-RS电路都展现出对这些非理想因素更高的容忍度,实现了更低的计算误差。
阅读原文:https://ieeexplore.ieee.org/document/9865136

