

-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
林宙辰教授、张牧涵助理教授揭示知识图谱的“开世界假设”如何影响模型评估
【字体: 大 中 小 】 时间:2022年12月27日 来源:北京大学新闻网
编辑推荐:
北京大学智能学院zero lab实验室林宙辰教授、博士生杨昊桐,北京大学人工智能研究院张牧涵助理教授合作,指出了当前的知识图谱补全度量标准可能会错误反映模型的强弱这一问题,给予理论和实验上的验证并提出了一些解决方案。

近日,北京大学智能学院zero lab实验室林宙辰教授、博士生杨昊桐,北京大学人工智能研究院张牧涵助理教授合作在NeurIPS 2022发表Oral论文“Rethinking Knowledge Graph Evaluation Under the Open-World Assumption”,指出了当前的知识图谱补全度量标准可能会错误反映模型的强弱这一问题,给予了理论和实验上的验证,并提出了一些解决方案。
知识图谱是一类存储结构化信息的数据结构,其中事物之间的关联以事实三元组(triplet)的形式保存。例如,一个地理信息知识图谱中就可能包括中国、首都、北京,用以表示中国的首都是北京。
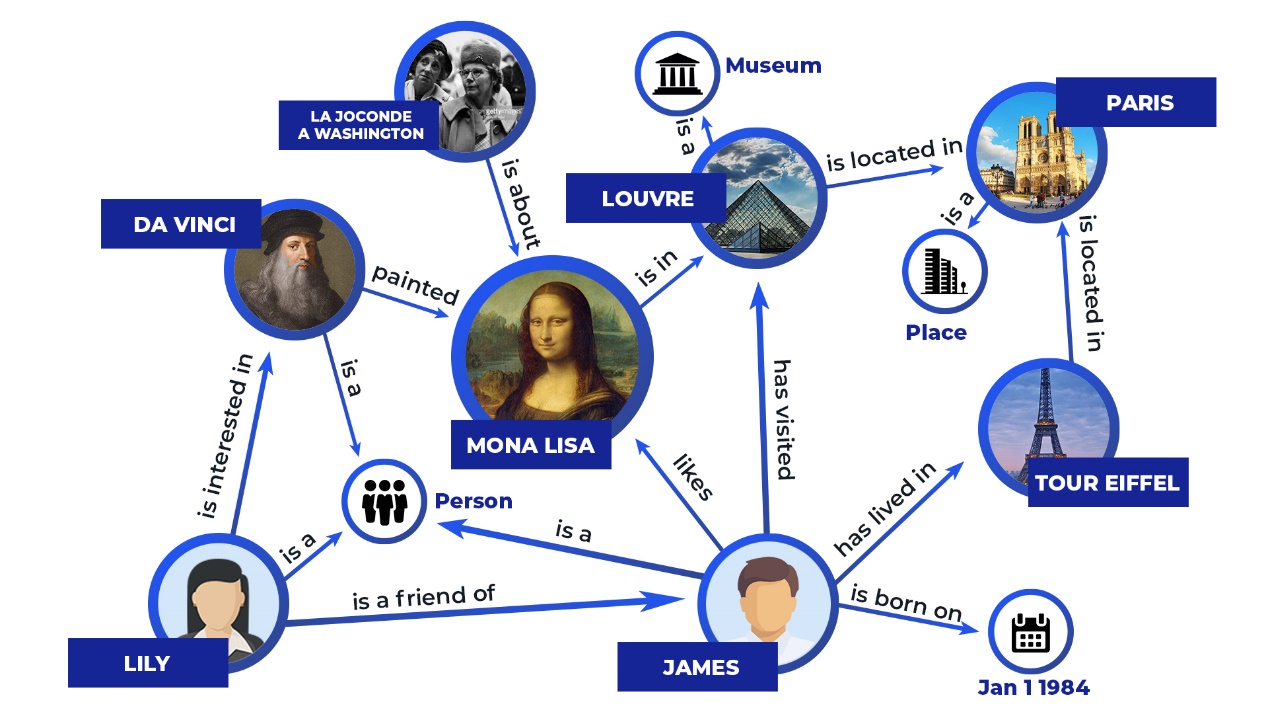
通过将实体表示为节点,三元组表示为一条有向边,可以将知识图谱表示为一个图,故名知识图谱。图片来源于网络
现有的知识图谱既有限定于某些具体领域的领域知识图谱,例如,医药知识图谱、地理知识图谱等,也有从网络维基百科中抽取的一般知识图谱。后者所包含的对象更多,关系更加复杂,较为知名的包括:YAGO知识图谱包括关于人物、城市、国家、组织和电影等的信息;WikiData则凭借着Wikipedia的广泛信息,拥有超过一亿个分属于不同类别的实体。

WikiData拥有超过一亿个对象的信息,图片来源:http://www.wikidata.org
知识图谱由于其结构化的存储方式,一个重要的应用是对知识进行自动推理。通过对存储信息的查询,知识图谱可以从某个实体出发,沿着某个特定的关系(谓词)寻找答案。这样的技术可以被用于问答系统、搜索引擎、专家系统等,为各类任务提供领域、常识和百科知识。
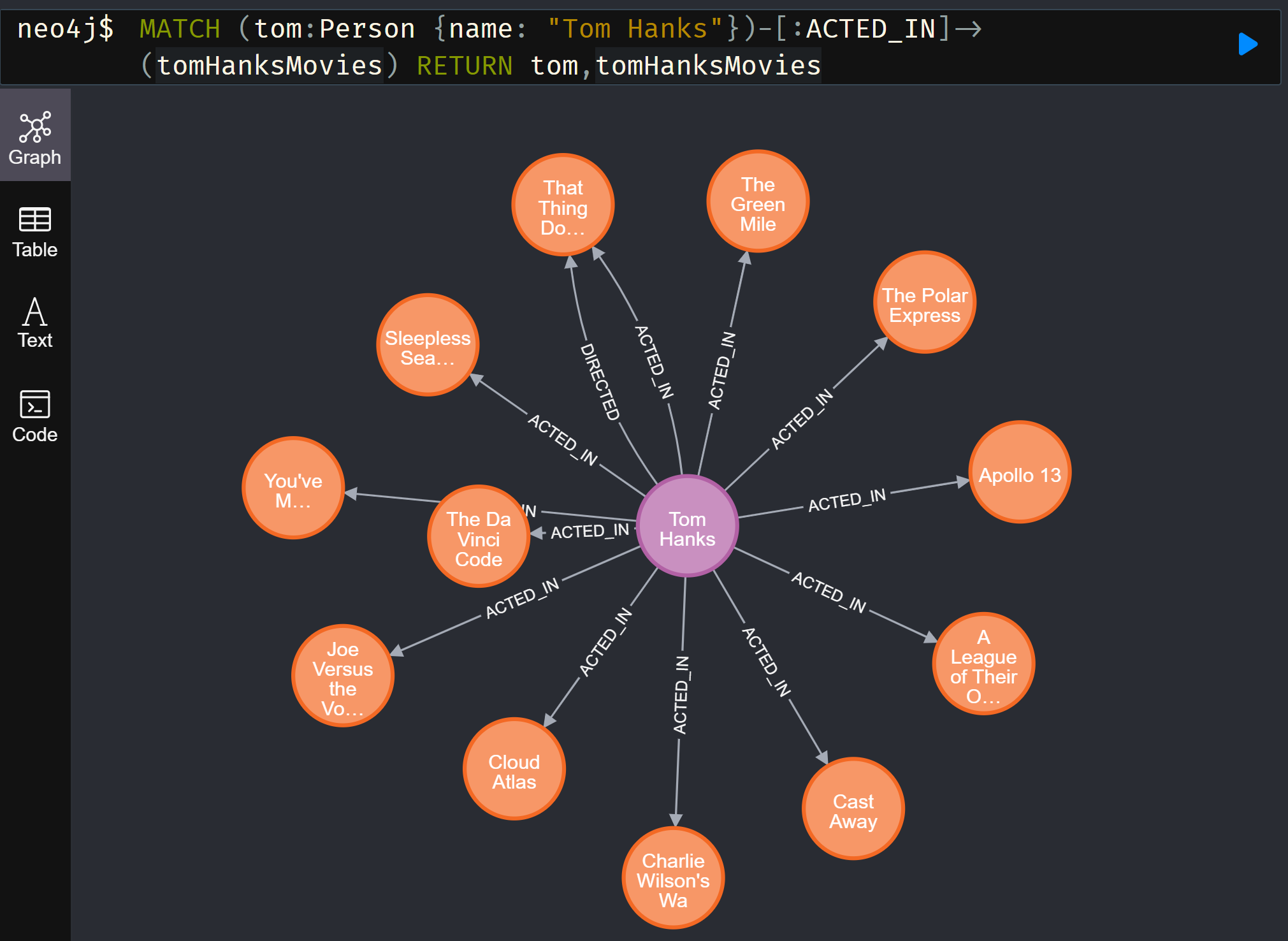
利用neo4j在知识图谱上进行可视化搜索
然而,由于知识图谱极大的规模和自动化生成的特点,其中可能存在信息缺失:即实际存在的事实可能没有被包含在知识图谱存储的三元组中。这种信息缺失将导致搜索无法得到完整的答案,影响知识图谱的应用。因此,知识图谱补全模型尝试通过在知识图谱的已有内容中进行学习,从而推理补充出知识图谱中缺失的事实。
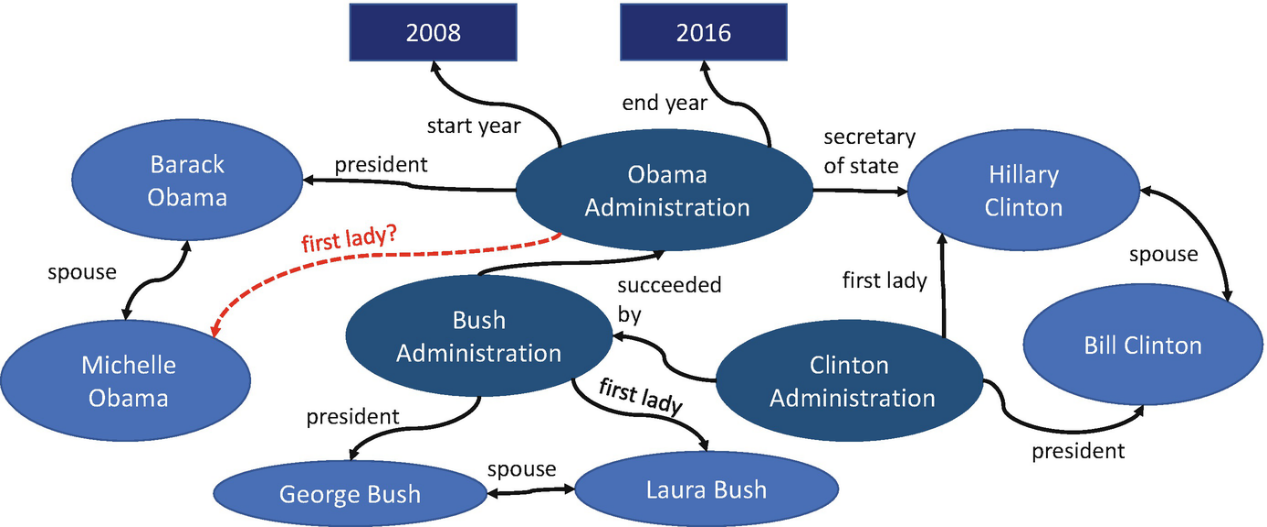
某些缺失事实可以通过已标注事实推理补充,例如,总统的配偶即为第一夫人
注意到,知识图谱一般只会显式地记录正确事实,缺少对错误事实的标注。因此,考虑到知识图谱中存在缺失事实的情况,针对一条没有出现在记录中的三元组,使用者无法判断它属于不应被包含的错误事实,还是属于被遗漏的缺失事实。这被称为开世界假设(open-world assumption,OWA)。而这一假设的反面,被称为闭世界假设,则认为不存在的三元组必然对应于假事实。这对应于一个被完全构建的知识图谱。

开世界假设和闭世界假设的不同
在对知识图谱补全模型进行评估时,由于问题本身基于知识图谱非完全,应当使用开世界假设。然而,现有的评估流程都是基于闭世界假设的,即,对于没有包含在测试集中的答案,都判定为错误答案。因此,这里存在实际评估过程与采用假设的不匹配问题。本文指出这一不匹配可能会导致在现有的评估方法下,存在评估度量退化(degradation)和不一致(inconsistency)的现象。作者将其称之为开世界问题。
为了研究这一问题,作者通过将测试集中的事实缺失和训练模型的预测正确建模为两个随机事件,推导出在有缺失情况下的评估度量的期望随模型强度的变化。在可接受的误差范围内,作者证明了对于最常用的度量:平均倒数排名(mean reciprocal rank,MRR),其期望呈现为对模型强度的对数曲线。这会导致度量退化的问题:首先,对于能够完全预测正确的模型,评估度量的期望无法达到理论最大值;同时,度量的增长由于其对数趋势而过于平缓,无法准确呈现模型强度的增长。
这种退化加之数值实验呈现出的较大方差,可能导致度量不一致的问题。即对于实际强度更强的模型,其度量可能更差;因此会导致模型之间强弱的错误比较。更进一步地,如果考虑到以上两个随机事件的相关性,作者进一步证明了模型偏差的存在,即度量会倾向于为负相关(即对于在测试集中缺失的事实,模型也更容易预测错误)的模型给出更高的评价。这种期望的不一致性无法通过更多的测试样例解决。
为了验证上述理论结果,作者生成了一个信息完全的家族谱图(family tree)数据集,然后从中随机删去一些事实以模拟现实的缺失数据集。在该数据集上,作者训练了各类知识图谱补全模型,在不同的缺失程度下都观察到了上述的度量退化和不一致现象。

如图所示的两个模型:M点代表的模型和红色线段上的一点代表的模型,在实际强度相差10%的情况下,评估度量给出了相反的结果(横轴为模型实际强度,纵轴为在缺失数据集上的评估)
作者指出,这种现象是由通常所采用的度量的“关注头部”(focus-on-top)的性质导致的。它要求度量对排序靠前的对象的位置变化更为敏感,这是为了模拟人类在进行评价时更为关注前置位的行为特点。然而,也正是这种敏感性使得在面对数据缺失时,度量会受到更严重的影响。为此,作者提出了一些更少“关注头部”的度量,并且基于理论和实验验证了这些度量的确可以减弱开世界问题对模型评估带来的影响。
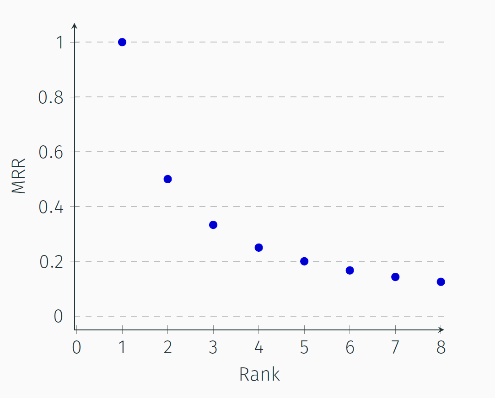
最常见的MRR,具有明显的“关注头部”的性质
该工作中,作者基于知识图谱的开世界假设,对常见的知识图谱补全的评估度量进行了数学上的推导和实验验证,证明了度量退化和不一致现象的存在;并指出了这种现象的原因在于度量的关注头部性质。作者提出,应当考虑加入“更少关注头部”的度量作为结论的验证,以避免不准确和不公平的比较。用一句话总结,当前的知识图谱补全度量标准并不完美,可能会错误反映模型的强弱,本文指出了这一问题,给予了理论和实验上的验证,并提出了一些解决方案。
涓嬭浇瀹夋嵎浼︾數瀛愪功銆婇€氳繃缁嗚優浠h阿鎻ず鏂扮殑鑽墿闈剁偣銆嬫帰绱㈠浣曢€氳繃浠h阿鍒嗘瀽淇冭繘鎮ㄧ殑鑽墿鍙戠幇鐮旂┒
10x Genomics鏂板搧Visium HD 寮€鍚崟缁嗚優鍒嗚鲸鐜囩殑鍏ㄨ浆褰曠粍绌洪棿鍒嗘瀽锛�
娆㈣繋涓嬭浇Twist銆婁笉鏂彉鍖栫殑CRISPR绛涢€夋牸灞€銆嬬數瀛愪功
生物通微信公众号


知名企业招聘
今日动态 | 人才市场 | 新技术专栏 | 中国科学人 | 云展台 | BioHot | 云讲堂直播 | 会展中心 | 特价专栏 | 技术快讯 | 免费试用
版权所有 生物通
Copyright© eBiotrade.com, All Rights Reserved
联系信箱:
粤ICP备09063491号












